FoLaR: Foggy Latent Representations for Reinforcement Learning with Partial Observability
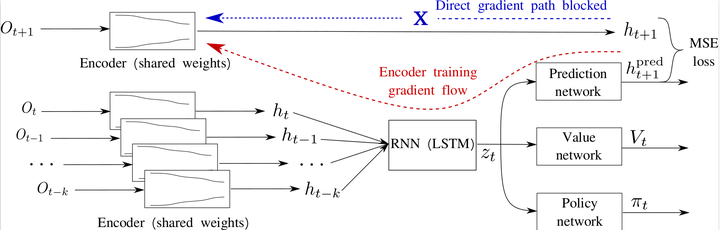 Model Architecture
Model Architecture
Abstract
We propose a novel methodology for improving the rate and consistency of reinforcement learning in partially observable (foggy) environments, under the broader umbrella of robust latent representations. The present work addresses partially observable environments, which violate the canonical Markov assumptions. We propose adaptations for any on-policy model-free deep reinforcement learning algorithm, in order to improve training in partially observable situations (i) recurrent layers for including information from previous observations, (ii) predicting the step reward and the next latent representation as auxiliary outputs from the same latent space as used for inferring the action, and (iii) modification of the loss function to penalise errors in the two auxiliary outputs, in addition to the reward-based gradients used for policy training. We show that the proposed changes substantially improve learning in several environments over vanilla Proximal Policy Optimisation (PPO) and other baselines in literature, especially in known challenging environments with hard exploration.