NeurIPS-2019 Summary
I presented my work on Pommerman at Deep Reinforcement Learning Workshop in NeurIPS this year, titled “Accelerating training in Pommerman with Imitation and Reinforcement Learning”, coauthors are Omkar Shelke, Richa Verma and Harshad Khadilkar. The selection of talks and posters to be visited was done primarily for Reinforcement Learning and to some extent NLP. Due to high rush during the poster session (one has to wait in queue for 30 minutes to enter poster session) and 4 parallel tracks during presentation, I have most probably seen 20-25% of the conference session. The main highlight for me was the socials which were introduced this year by NeurIPS for having informal discussions with prominent people in the field. I attended RL social and had a detailed discussion with Richard Sutton, David Silver, Martha White, Michael Littman etc, over topics ranging from causality in RL to going away with the MDP settings in the RL. All in all, it was an enlightening experience to have a deep philosophical discussion, especially with Sutton. The common notion that resonated with all of them was to have a big picture in mind, before delving down to a very specific problem. If building an AGI is the ultimate goal, try to place your work in that context and work from there.
In RL, people have been looking at sample efficient RL, batch RL, meta-learning and towards ablation studies of existing algorithms. It would not be correct to gauge the overall direction of community as I did not attend all of the talks, going through the papers and posters I did find that lot of work has been towards having much more deeper understanding towards the theory of deep learning. Talks and most of the workshops were recorded and recordings are available at https://slideslive.com/neurips/ . This report is short summary of some of the talks/tutorials I attended, and a list of things that I found interesting during the conference.
Tutorials
Imitation learning and its application to Natural Language Generation
Given by: Kyunghyun Cho, Hal Daume III
The tutorial focuses on using imitation learning and reinforcement learning in NMT (Neural Machine Translation), dialogues and story generation. The main challenge in the using Beam search for searching is lack of diversity and in the literature mostly it is tackled by adding noise. Reinforcement learning with its stochastic policies can have a great improvement here, especially when we want to have more natural dialogues, stories which are not similar yet have a structure of plots and make sense etc. The story examples given by the authors were really impressive.
Efficient Processing of Deep Neural Network: from Algorithm to Hardware
Given by: Vivienne Sze
The tutorial provides insights into designing efficient hardware for DL. They focus on different constraints such as speed, latency, energy consumption and cost. All of these constraints require a careful trade-off between each other. For example as shown in the figure below, where we can increase the speed of convolution at the expense of data duplication.
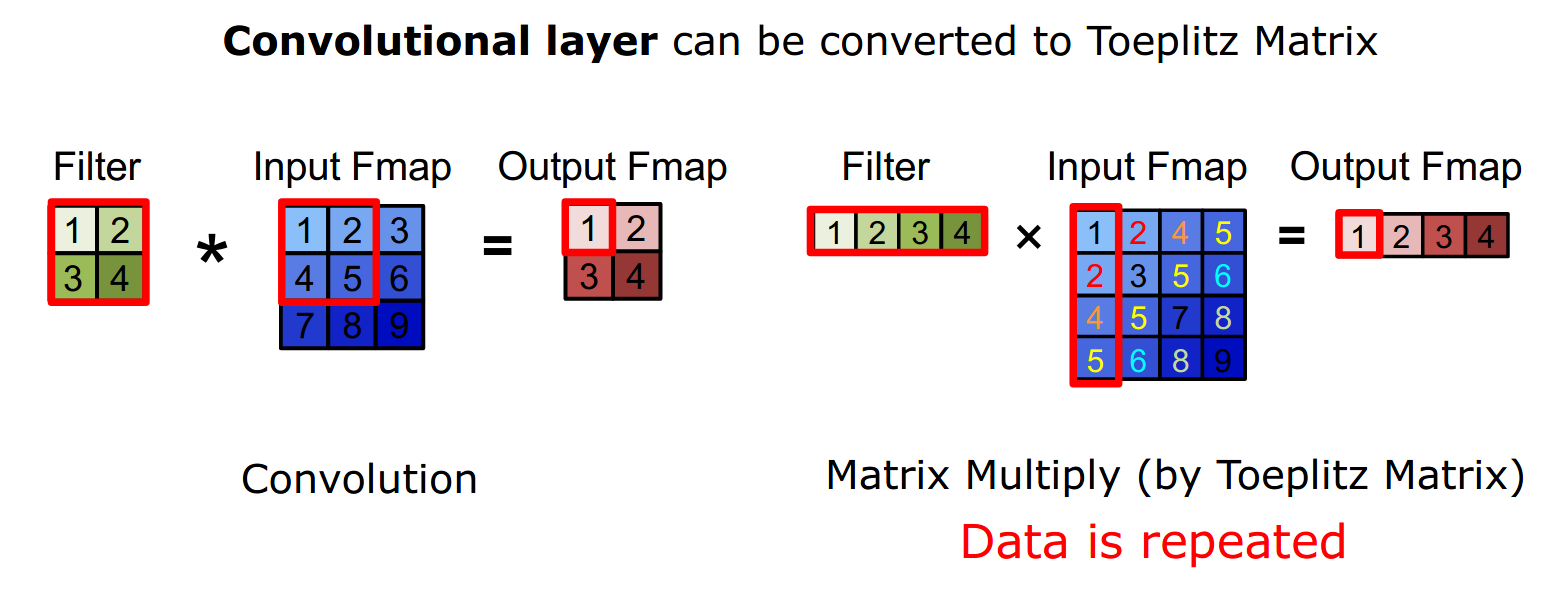
They discuss architecture such as CPU and GPU to task-specific architectures of FPGA. Most of the presentation was focused on optimizing the hardware for Image processing and vision task.
Reinforcement Learning: Past, Present and Future Perspectives
Given by: Katja Hofmann This was a very elaborate session of RL, from basic MDP formulation to Multi-agent RL with a different perspective in generalization and evaluating policies. Minecraft case study was very interesting for long term reward and exploration.
Invited Talks/Keynotes
Celeste Kidd: How to know
Questions:
- How do we know, what we know
- How do two people living in the same world come to believe very different things
- Why do people believe somethings which aren’t true
- Age of information and also misinformation
- How do we form Belief
- Vast amount of knowledge present in the world, an individual learner has to pick and choose what to learn and how to learn, how does one decide that
We need to answer all these questions because we will need to build much more accurate models of the world and have this knowledge embedded in the AI agents. Her work is around mostly inferencing on what babies infer in the real world, what do they look, where to they focus, what kind of prediction they make. Similar work was discussed by Josh Tannenbaum in his last year’s ICML talk
Five Key things
- Humans continuously form beliefs (It’s not a one-step process) –> think of it as a probabilistic expectation. (Humans tend to lose attention if things are too predictable or too surprising, picking a book which one knows (redundancy) is boring to read whereas picking a book written in the language which you don’t even understand (absolute new information) is also not fun to read)
- Certainty diminishes interest, an agent should be smart enough to not learn and waste resources on which it is certain about, humans do that. However, we are often wrong about things which we are certain about. We have a very poor model of our own uncertainty.
- Certainty is driven by feedback. When feedback is not available our feedback might be way off.
- Less feedback may encourage overconfidence. Small confirmatory feedback is enough to solidify some concepts and lead to wrong assumptions about concepts. Given the diversity in the concepts for the same object, are people aware of the weird behaviour about the notion of the concept that they have.
- Humans form beliefs quickly. The algorithms pushing content online have profound impacts on what we believe.
She talked about the work toxicity for women and how small instances of false accusation has created a fear among men. She emphasized when women complains and talks about some bad things that she has gone through, chances are she as went through much more than that. Standing Ovation by the crowd.
Test of time, Lin Xiao: Dual Averaging Method for Regularized Stochastic Learning and Online Optimization
Two main ideas which were dominant/promising direction in 2009, Stochastic Gradient Descent and Online Convex Optimization. Other important works during early 2000’s compressed sensing/sparse optimization, interior point methods, proximal gradient methods. Paper explores combining SGD with sparse optimization.
Yoshua Bengio: From System 1 Deep Learning to System 2 Deep Learning
Motivation
Questions: is it enough to have more data, compute, large models? How far are we from Human-level AI.
We need to think more tangential to the DL paradigm. Inspiration: “Thinking Fast and Slow” by Daniel Kahneman. System-1,2 is also same as describe in podcast of
Sean Carroll
System 1 –> Intuitive, fast unconscious non-linguistic, and habitual decision making/inference. (DL is good at this)
System 2 –> Slow, logical, sequential, conscious, linguistic, algorithmic,decision making. (DL is not equipped to deal with this)
Things missing in DL
- Out of distribution generalization and transfer
- High level cognition: need to move from system 1 to system 2 –> High level semantic representation, causality
- Machines that understand the world by building world models, Knowledge seeking mechanism
Talk
- ML Goal: Handle Changes in Distribution
- System 2 Basics: Attention and Consciousness
- Consciousness Prior: Sparse Factor Graph
- Theoretical framework: meta-learning, localized change hypothesis causal discovery
- Compositional DL architectures
Michael Littman on Assessing the Robustness of Deep RL Algorithms
Motivation for this talk was to understand, why any decisions are taken by a policy in certain scenarios (DQN for atari as example), build a Saliency map by masking of portions of state space. Conclusion being, DQN does not learn the statespace as we see it, although it has strategies to win the game it does not understand the game per say. Evaluation metrics for generalization Value Estimation Error, total accumulated reward.
Oral/spotlight Presentation
Towards Explaining the regularization effect of initial large learning rate in training neural networks

Authors explain the effect of learning rate on patterns that are learnt. They prove that having a lower learning rate learns very myopic structure, where as larger learning rate learns the overall/macro structure. They prove that over a CIFAR dataset, where they super-impose a patch of image over the original image in the dataset. The Image from the dataset can be considered to hard-to-generalize but easy-to-fit sample, whereas small patch can be considered as easy-to-generalize but hard-to-fit sample.
Sample Complexity of Deep Neural Networks via Lipschitz Augmentation
Objective is to prove upper bounds on generalization error and improve with regularization. The norm of weights is not sufficient for getting upper bounds, instead make it is a function of data.
Outstanding New Directions Paper: Uniform Convergence may be unable to explain generalization in deep learning
Objective of this work was to understand why does over-parameterized networks generalize well. The generalization error or the bound does not just depend on the parameters but also on the training set size. Uniform convergence does not explain the generalization.
On Exact Computation with an Infinitely Wide Neural Net
Work was based on relationship between the width of the Neural network and neural tangent kernel. On the lines of understanding larger width networks can achieve zero prediction errors. NTK performance is comparable to CNNs.
Generalization Bounds of SGD for Wide and Deep NNs
Key ideas: Deep ReLu nets are almost linear in parameters in a small neighborhood around initialization, Loss is Lipschitz continuous and almost convex
Causal Confusion in Imitation Learning
Imitation learning: powerful mechanism for learning complex behaviors. Behavioral cloning is imitation learning with supervised settings. But the imitation policy fails the moment it encounters state which it has not seen during behavior cloning, and there is catastrophic degradation in the policies (Distributional shift in the data).
Does more information mean better performance –> Not necessarily


Behavior cloning learns to brake when the brake light is on!!!! Just having the information about the road is more generalized. Giving more information leads to confusion. Ways to tackle is predict actions conditioned over causes and Targeted intervention by expert queries.
Imitation Learning from Observations by Minimizing Inverse Dynamics Disagreement
This work was on imitation learning when you need to learn the expert policy with just state/observations. They argue that the difference between the imitation learning and learning with just state spaces is proportional in the disagreement of actions in the actions and expert (GAIL).
Learning to Control Self-Assembling Morphologies: A study of Generalization via Modularity
Authors propose to have lego kind of modules with each module taking inputs+message and generating outputs + message. This settings can lead to much more robust policies in co-operative environment. Co-Evolution of control and morphology. Policies are shared along the modules and hence they learn much more robust policies. Link to the video https://youtu.be/cg-RdkPtRiQ, last part of the video where, it accomplishes the task even with losing some modules is spooky.
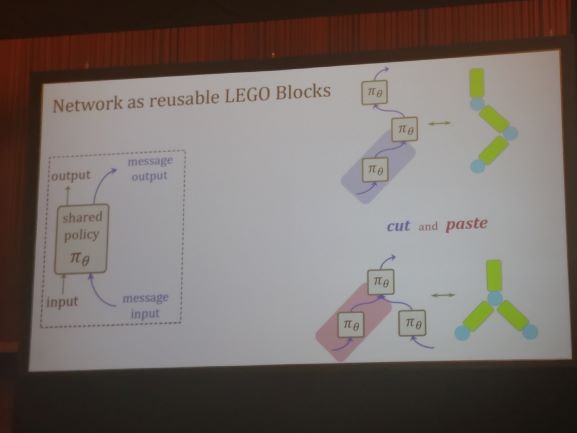

A Structured Prediction Approach for Generalization in Cooperative Multi-Agent Reinforcement Learning
Objective: Find policies that generalize to new agent-task pairs not seeing during training.
Compute score on previous pairs, using structured inference, use this to infer new policy on new pairs. Add a new constraint to the optimization to make it a linear program. The constraint encourages agents to cooperate. Further extend the LP to a quadratic program.
Guided Meta-Policy Search
RL is very sample inefficient. Meta-Learning is one possible solution to this problem by making efficent use of previous training tasks. Most meta-RL methods also requires huge amounts of data for the training phase, even if the adaptation is efficient. Also shortcomings in exploration and credit assignment during the training phase.
Solution, train on each task separately. Then train a meta-policy in a supervised manner from earlier policies.


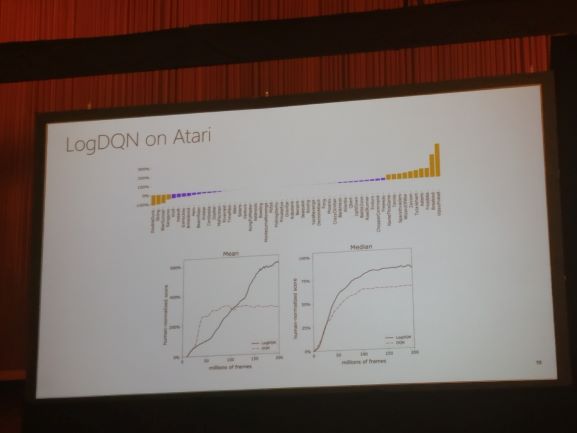
Using a Logarithmic Mapping to enable Lower Discount Factors in Reinforcement Learning
For Infinite horizon, the gamma decays exponentially. Therefore most of the gammas need to be near 1 to be meaningful for infinite horizon tasks. However, this makes learning hard. Experiments show that with low gamma policies are very bad. Action Gap is defined as difference in Q values for a given state between optimal action and action taken. They prove that with low discount factors the action gap is large.
They present the Log(Q) values instead of Q value

Better Exploration with Optimistic Actor Critic
Being too Greedy is bad. However, Policy gradient methods are greedy. Solution is to use Conservative update which reduces overestimation. However this leads to conservative policies which do not explore much. They provide upper bound to critic values instead of lower bound, which leads to optimistic estimation. They improve of SAC.
Robust Exploration in Linear Quadratic Reinforcement Learning
Robust Exploration $\rightarrow$ does not cause catastrophic degradation of policy. Targeted Exploration $\rightarrow$ knowledge which can improve the task solving capabilities. They formulate the exploration-exploitation problem into convex optimization problem.
Tight Regret Bounds for Model-Based Reinforcement Learning with Greedy Policies
Minmax Regret bounds for Model-based RL based on short term and long term planning. They show that short-term planning (one step planning) is minmax optimal with finite horizon MDPs.
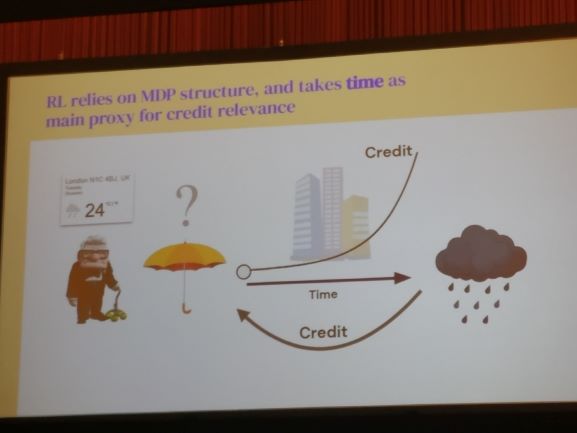
Hindsight Credit Assignment
Usually, the credit assignment is done with temporal scale and assume that noisy assignment would eventually be able to learn the long term action-consequences. Man has to figure out what caused him to be wet during the day. As an RL algorithm, he would spend many days getting wet by not bringing an umbrella. They solve this by explicitly learning the relevant credit using posterior probabilities.

Weight Agnostic Neural Networks
Why are CNNs much better than Fully-connected layers. No matter how much you increase the width of FC layers it would not beat CNNs. The answer lies in the structure of CNNs. This works explores how much far just the structure of Neural Networks can take us without relying on the weights. They create a initial population of structures with connections and then initialize with different weights for each structure. Without training they evaluate the performance of all the structures and pick out top K candidates. Perform 5 additional operations such as addition of nodes, addition of connections etc and do the procedure repeatedly. They show that structure alone can lead to 82% accuracy over MNIST dataset without training.

A neurally plausible model learns successor representations in partially observable environments
This paper was about representation of belief states with he help of distributed distributional code and successor features. They derive the connection between these two from neuroscience. They also generalize this over POMDPs
DualDICE: Behaviour-agnostic estimation of discounted stationary Distribution Corrections
How can we estimate average discounted return for a particular policy for off policy algorithms as the experience collection is done over varied number of policies. They propose a change in the loss function based over ratio of density problem (similar to PPO) with importance of weighting trick.
VIREL: A Variational Inference Framework for Reinforcement Learning
Look at RL as probabilistic inference problem. People have tried Pseudo-likelihood methods (risk taking) and Maximum entropy objective (such as SAC, however they have issue of non-recoverable of optimal policies). They present actor-critic methods with expectation maximization with much better sample efficiency.
Posters
RL
- Doubly-Robust Lasso Bandit - Gi Soo Kim, Myunghee Cho Paik - Seoul National University
- Decentralized cooperative stochastic bandits - David Martinez-Rubio, Varun Kanade, Patrick Rebeschini - Oxford
- Multi-agent Common knowledge Reinforcement Learning - Christian A. Schroeder de Witt, Jakob N. Foerster, Gregory Farquhar, Philip H. S. Torr, Wendelin Boehmer, Shimon Whiteson
- Meta-Learning with Warped Gradient Descent - Sebastian Flennerhag, Andrei A. Rusu, Razvan Pascanu, Hujun Yin, Raia Hadsell
- Measuring the reliability of RL algorithms - Stephanie C.Y. Chan, Sam Fishman, John Canny, Anoop Korattikara, Sergio Guadarrama
- Adaptive Online Planning for Continual Lifelong Learning - Kevin Lu, Igor Mordatch, Pieter Abbeel
- Learning Efficient Representations for Intrinsic Motivation - Ruihan Zhao, Stas Tiomkin, Pieter Abbeel
- Harnessing Structures for value based planning and reinforcement learning - Yuzhe Yang, Guo Zhang, Zhi Xu, Dina Katabi
- Benchmarking Safe Exploration in DRL - Alex Ray, Joshua Achiam, Dario Amodei
- Search on the Replay Buffer: Bridging Planning and Reinforcement Learning
NLP
- Landmark Ordinal Embedding - Nikhil Ghosh, Yuxin Chen, Yisong Yue
- Text based interactive recommendation via constraint-augmented reinforcement learning - Ruiyi Zhang, Tong Yu, Yilin Shen, Hongxia Jin, Changyou Chen
- Model based Reinforcement learning with adversarial training for online recommendation - Xueying Bai, Jian Guan, Hongning Wang
- Stochastic shared Embeddings: Data Driven Regularization of Embedding Layers - Liwei Wu, Shuqing Li, Cho-Jui Hsieh, James Sharpnack
- Quantum Embedding of Knowledge for Reasoning - Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
- Can Unconditional Language Models Recover Arbitrary Sentences? - Nishant Subramani, Sam Bowman, Kyunghyun Cho
- Interpreting and Improving natural-language processing (in machine) with natural language-processing (in the brain) - Mariya Toneva, Leila Wehbe
Misc
- ZO-AdaMM: Zeroth-Order Adaptive Momentum Method for BlackBox Optimization - Xiangyi Chen, Sijia Liu, Kaidi Xu, Xingguo Li, Xue Lin, Mingyi Hong, David Cox
- High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks - Ruben Villegas, Arkanath Pathak, Harini Kannan, Dumitru Erhan, Quoc V. Le, Honglak Lee
- Adversarial Examples are Not bugs, they are features - Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, Aleksander Madry
- Dynamic of stochastic gradient descent for two-layer neural networks in the teacher-student setup - Sebastian Goldt, Madhu S. Advani, Andrew M. Saxe, Florent Krzakala, Lenka Zdeborová
- Poincare recurrence, cycles and spurious equilibria in gradient-descent-ascent for non-convex non-concave zero-sum games- Lampros Flokas, Emmanouil-Vasileios Vlatakis-Gkaragkounis, Georgios Piliouras
- Computational Separations between Sampling and Optimization - Kunal Talwar
- Learning Imbalanced Datasets with Label-distribution-aware Margin Loss - Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, Tengyu Ma
- vGraph: A Generative Model for Joint Community Detection and Node Representation Learning - Fan-Yun Sun, Meng Qu, Jordan Hoffmann, Chin-Wei Huang, Jian Tang
- Putting an End to End-to-End: Gradient Isolated learning of Representations - Sindy Löwe, Peter O’Connor, Bastiaan S. Veeling
Hardik Meisheri
Senior Applied Scientist
My research interests include Reinforcement Learning and Natural Language Processing.